
昨今の生成AIブームに伴い、目にする機会が増えた“LLM”。しかしそれが一体何なのか、実はよくわかっていない…という方も多いのではないでしょうか?
そこで今回は、LLM(大規模言語モデル)とは何か、関連する用語と合わせて、初心者向けにやさしく解説していきます。
また、その仕組みや生成AIなどの関連する用語との違いについてもご紹介しますので、ぜひ最後までご覧ください。
- LLM(大規模言語モデル)の概要
- LLM(大規模言語モデル)に関連する用語の意味
- LLM(大規模言語モデル)の課題や注意点
目次
LLM(大規模言語モデル)とは?
まずLLM(大規模言語モデル)とは何か、一般的には以下のように説明できます。
LLM(Large Language Model/大規模言語モデル)は、自然言語処理(NLP)のタスクにおいて、深層学習技術(ディープラーニング)と大規模なデータセットを利用する言語モデル。生成AIの一種であり、一般的な言語理解と生成の能力を備えている。
大規模言語モデルは通常、トランスフォーマー(Transfomer)アーキテクチャに基づいており、膨大な量のテキストデータでトレーニングされ、言語のパターン、文脈、および意味を学習している。
一般的に見られるこのような説明は、専門用語が多くわかりづらい…と思いませんか?
そこで、もう少し説明を簡単にすると以下のようになります。
LLM(大規模言語モデル)とは、生成AIの一種であり、「コンピュータが人間の自然言語を理解・処理・生成すること」に特化した言語モデルのこと。人間が使う言葉の曖昧さや文脈を的確に読み取り、複雑なタスクに対応できる。
「Transformer」という種類の深層学習(ディープラーニング)モデルを基盤とし、大量のテキストデータを使用して、複雑なパターン認識などの学習・トレーニングが行われている。
まだまだ難しい…!
ということで、ここからはLLMに関連する用語を一つ一つ見ていきましょう。
- 言語モデル
- 生成AI
- 自然言語処理(NLP)
- 機械学習
- 深層学習技術(ディープラーニング)
- トランスフォーマー(Transfomer)アーキテクチャ
それぞれ解説していきます。
言語モデル
LLM=「大規模言語モデル」ですが、そもそも「言語モデル」とは何でしょうか?
結論から言うと「言語モデル(Language Model)」は、言語の統計的な構造やパターンを学習し、文章の生成、評価、テキストの予測などの言語タスクに用いられるモデルのことです。
「モデル」とは、データのパターンや関係性を捉え、それに基づいて新しいデータに対して予測や解析を行うための枠組みやアルゴリズム(課題解決や目標達成のための計算方法・処理手法)を指します。
言語モデルは、文脈に応じて、次に続く単語や文字の出現確率を予測します。これにより、与えられた文脈に基づいて、次に来る単語や文字を自動で生成することが可能になります。これは文章生成や文章の自動補完、機械翻訳、質問応答などに応用され、特に自然言語処理(NLP)の分野で広く利用されています。
近年では、ディープラーニング(後ほど解説)の進歩により大規模な言語モデルが注目されています。例えば、GPT(Generative Pre-trained Transformer)は主要な大規模言語モデルの一つです。GPTシリーズのモデルは、膨大なデータセットを用いて事前学習され、多様な言語タスクに適用できる柔軟性を持っているのが特徴的です。
つまり、「言語モデル×ディープラーニング×大量のテキストデータ学習」という組み合わせによって、より幅広いデータ処理に対応できるようになった言語モデルが「大規模言語モデル(LLM)」と言えます。
生成AI
生成AI(ジェネレーティブAI/Generative AI)とは、テキストや画像、音声、動画などさまざまなコンテンツを0から自動生成できるAIのことです。
従来のAI(人工知能)は、人間の手で学習させた既存のデータの中から、適切な回答を「選択し提示する」ことしかできませんでした。これに対し生成AIは、学習したデータを組み合わせ、自律的に「回答を自動生成」することができます。
具体的には、OpenAIのChatGPTやGoogleのBard、MicrosoftのCopilot・Bing Chatなどが代表的な生成AIツールとして挙げられ、これらはテキストや音声、画像、プログラミングコードなど多岐にわたるコンテンツの生成が可能です。


この他にも、画像生成に特化した「画像生成AI」、音声特化の音声生成AIなど、生成AIの中でもいくつか種類があることも押さえておきましょう。


自然言語処理(NLP)
自然言語処理(Natural Language Processing/NLP)は、機械が人間の使用する自然言語(日常的な話し言葉や書き言葉など)を理解し、処理するための分野を指します。
NLPの目的は、コンピュータが言語に対して、より人間のような理解力を持ち、適切な応答や処理ができるようにすることです。機械が自然な言語のテキストや音声を理解し、解釈し、生成するために使用されます。
NLPは機械学習や人工知能の一部であり、テキストデータや音声データを取り扱うための様々な技術やアルゴリズム(モデル)が組み合わさっています。
具体的なNLPのタスクには、テキストの解析や情報抽出、文書分類、機械翻訳、対話型の質問応答システムの構築などがあります。
近年、ディープラーニングや大規模な言語モデル(例:GPTシリーズ)の進化により、NLPの性能が向上し、様々な実用的な応用が広がっています。
機械学習
機械学習(Machine Learning)は、コンピュータがデータから学習し、経験に基づいて新しい情報を予測・判断する能力を獲得するプロセスを指します。
これはプログラミングではなく、データとアルゴリズムによってコンピュータが自動で、自己学習を行うものです。
機械学習の主な種類には、教師あり学習(Supervised Learning)、教師なし学習(Unsupervised Learning)、強化学習(Reinforcement Learning)があります。
機械学習の主な3種類
教師あり学習:
モデルは人間によってラベル付けがされたトレーニングデータから学習し、新しいデータに対して予測を行います。「ラベル付け」とは、例えばあらかじめ用意していたリンゴの写真に「これはリンゴ」と名前を付けておくことです。教師あり学習ではこのようなデータを人間の手で用意する必要があります。
教師なし学習:
ラベルが与えられず、データの構造やパターンをモデルが自ら発見します。例えばあらかじめ用意していたリンゴの写真に「これはリンゴ」とラベル付けするのではなく、様々なデータの中から特徴を発見させ、学習させる手法です。
強化学習:
エージェント(学習するコンピュータなどの主体のこと)が環境と相互作用し、特定のアクションの結果得られる報酬(利益や損失)を最大化するように学習します。報酬を最大化させることで、効率的な繰り返しの学習(試行錯誤)を実現することができます。
機械学習は、画像認識、音声処理、自然言語処理、金融予測など多岐にわたって応用されています。
モデルの学習や予測には統計学や確率論の概念が組み込まれ、近年ではディープラーニングなどの手法が注目を集めています。
深層学習技術(ディープラーニング)
深層学習技術、またはディープラーニング(Deep Learning)は、機械学習の一種で、人間の脳の構造に触発された「ニューラルネットワーク(Deep Neural Network/DNN)」と呼ばれる層状の構造のモデル(深層学習モデル)を使用して、複雑なパターン認識や表現、問題解決を学習する手法です。
以下はディープラーニングの主な特徴です。
多層の階層構造
ディープラーニングでは、通常、多くの中間層(隠れ層)を持つニューラルネットワークが使用されます。
中間層(隠れ層)とは、入力層から受け取った(入力された)複雑なデータを、処理しやすい状態に変換した後、単純化して、単純な情報しか扱えない(出力できない)出力層に受け渡すという、仲介者の役割を果たします。
この中間層(隠れ層)が多層であればあるほど、複雑な情報データに対応できます。各層で異なる情報処理のアプローチが行われ、それぞれで処理・変換できるデータの種類が異なるためです。
例えば、リンゴ(元となるデータ)が入力された場合、中間層①形部門、中間層②色部門、中間層③ツヤ部門、中間層④…などと様々な階層がリンゴの情報をそれぞれ抽出します。このため中間層が多いほど、理解できる情報の種類が増え、より複雑なデータにも対応できるようになるのです。
高度な特徴抽出
多層の階層構造(ニューラルネットワーク)により、高度な「特徴抽出」や、表現の学習が可能になります。
ここでの「特徴(feature)」とは、「特徴量」とも呼ばれる、機械学習やディープラーニングの文脈における専門用語で、コンピュータがデータを理解するために必要な要素を指します。
例えば、人はリンゴを見ればそれをリンゴであると判断できますが、コンピュータにはできません。
コンピュータがリンゴを見てリンゴであると理解するためには、リンゴであることを裏付ける特徴(例えば赤い、丸いなど)を抽出し、その上でコンピュータが理解できるような「数値」に変換しなければなりません。これが特徴(量)抽出と呼ばれるプロセスです。
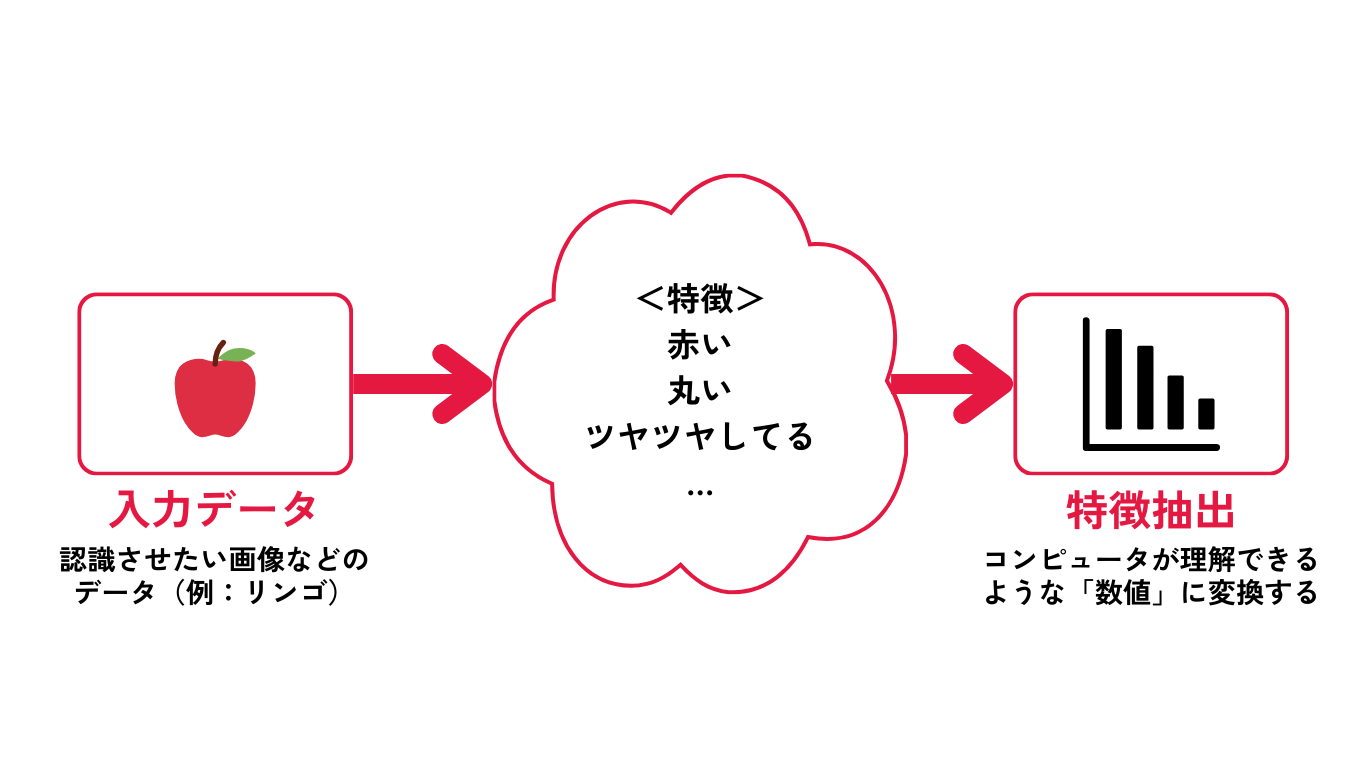
図:特徴量とは – 【AI・機械学習用語集】 を参考に筆者作成
つまり「高度な特徴抽出」とは、元となるデータ(上記の例ではリンゴに該当)から、幅広い特徴の抽出が可能になることで、コンピュータのデータ処理や理解能力が向上することを示します。
「幅広い特徴の抽出が可能になる」とは、低レベルの特徴から高位の抽象的な特徴を幅広く学習したり、処理したりできるということです。
例えば、画像データの場合、ピクセルの値や色が低レベルの特徴(機械が理解しやすい)であり、物体の形状や概念(機械が理解しにくい)が高位の特徴となります。
大量の学習データ
ディープラーニングは大量のデータが必要です。モデルは膨大なデータセットから学習し、一般的なパターンや特徴を抽出します。
自動的な特徴抽出
伝統的な機械学習では手動で特徴を選択する必要がありますが、ディープラーニングではモデルがデータから自動的に特徴を学習します。
トランスフォーマー(Transformer)アーキテクチャ
GPTシリーズをはじめとするLLM(大規模言語モデル)は、基本的に「Transformer(トランスフォーマー)」という学習モデルに基づいて構築されています。このTransformerとは、2017年6月12日にGoogleにより発表された、主に自然言語処理 (NLP)の分野で使用される深層学習モデルです。
Transformerは、自然言語や「時系列データ」(特定の期間で、時間の経過に伴って変化するデータ全体)を処理して、翻訳やテキスト要約などのタスクを実行するために設計されています。
通常、この種のタスクには「回帰型ニューラルネットワーク(RNN)」というモデルが使われますが、Transformerは異なるアプローチを採用しています。
Transformerの特徴として、時系列データを逐次処理する必要がないという点が挙げられます。
言い換えると、データが保存された順に一つ一つ処理を行うのではなく、順番を問わず並列して処理を行うことができるということです。
例えば、自然言語の文章を入力する場合は、文頭から文末までを順に処理する必要はありません。なぜなら、文頭から文末まで、並列して同時に処理することができるためです。
これにより、時系列データを順に処理する回帰型ニューラルネットワーク(RNN)と比べ、トレーニング時間が大幅に短縮され、大量のデータを効率的に学習できます。
LLM(大規模言語モデル)と関連する用語との違い
LLM(大規模言語モデル)と生成AI
LLMは生成AIの一部です。生成AIのうち、自然言語処理技術に特化したモデルをLLM(大規模言語モデル)と言います。
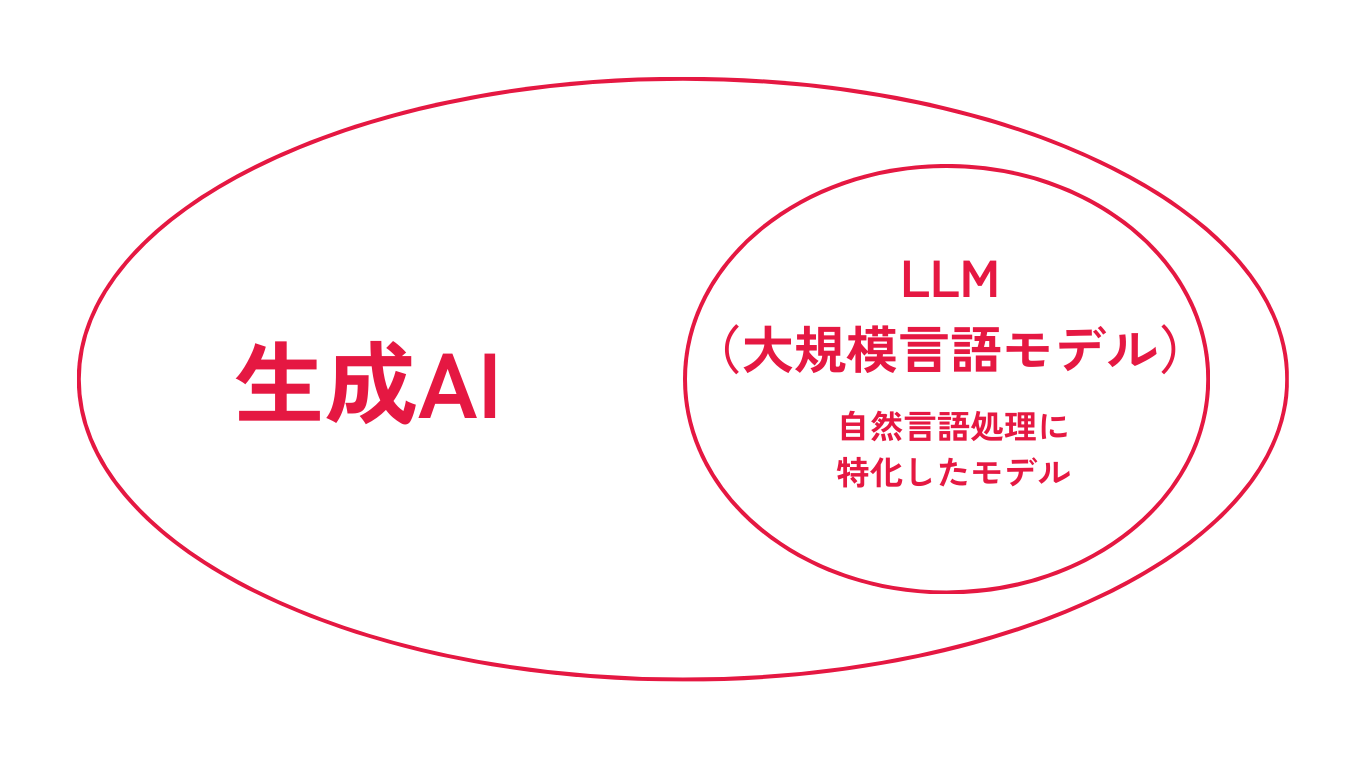
生成AIは、自然言語処理を含む、画像、音声などの自動生成など、さまざまなデータ生成に対応するAI技術全般のことを指します。OpenAIのChatGPTもこの生成AIツールの一つです。
LLM(大規模言語モデル)と機械学習・深層学習(ディープラーニング)
LLMは、「機械学習」モデルの1種である「深層学習(ディープラーニング)」モデルを使用して、大量のテキストデータを学習しています。LLMが人間の自然言語を理解できるのは、機械学習のうちの深層学習による大量のデータ学習の成果なのです。
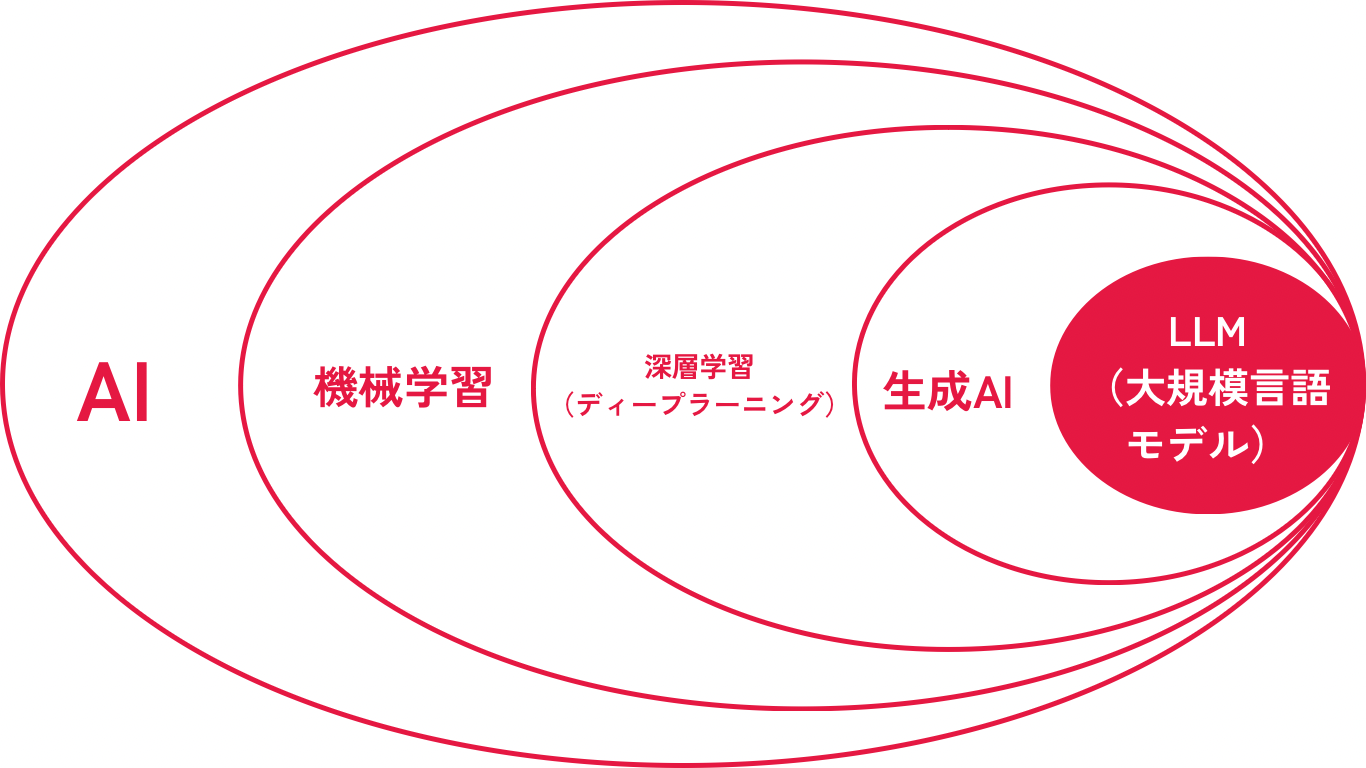
機械学習および深層学習は、AI技術のうち、モデルの学習の手法やシステムを指します。LLMはそれを活用した技術である生成AIのうち、テキストベースのタスクに特化した言語モデルの一つを指します。
LLM(大規模言語モデル)の仕組み
LLMがテキストデータを入力し出力するまでの仕組みは、大まかに以下のような流れになっています。
- データを数値化し、コンピュータが理解・処理しやすくする
- 文脈を理解する
- 次に続くテキストを予測する
- 文章を出力する
もう少し詳しく説明すると、以下のような8つのステップに分けられます。
仮に、「大規模言語モデルは面白いですか?」と入力したとして、各Stepでの具体例を提示していきます。ただし、以下の説明は初心者にもわかりやすくするために簡易化した一例であり、実際のものとは異なる点ご容赦ください。
Step1:トークン化(Tokenization)
テキストデータを「トークン」に分割し、単語や文字ごとの最小単位に変換します。これによりコンピュータが人間の自然言語や文脈を理解しやすくなります。
【例】
「大規模言語モデルは面白いですか?」という文章をトークン化する(トークンごとに区切る)と以下のようになります。
[”大規模“, “言語“, “モデル“, “は“, “面白い“, “ですか“, “?“]
トークンとは、「単語」や「文字」とは異なる、コンピュータが使用する言葉の最小単位です。
トークンについて詳しい解説は、下記記事をご参照ください。

Step2:ベクトル化
トークン化はテキストを単位(トークン)に分割し、ベクトル化はそれを数値データに変換します。この段階を「エンベディング」と呼ぶこともありますが、これは数値を作り出す手法の一つであり、単語の意味をその数値に反映させるものです。
テキストのトークン化とベクトル化によって単語の意味や関係性が数値で表現でき、コンピュータでも人間の言葉が理解できるようになります。
【例】
「大規模」:ベクトル [0.2, 0.5, -0.1]
「面白い」:ベクトル [0.8, -0.3, 0.6]
というように、トークン化された単語をベクトル化します。
Step3:ニューラルネットワークの層を通過
ベクトル化されたトークンは、その後、言語モデルを構成する多層のニューラルネットワークを通過します。これらの層には畳み込み層、アテンション層、全結合層などが含まれ、情報の抽出や理解に使用されます。
Step4:コンテキストの理解
モデルは前後のトークンの関係性を学習し、文脈を理解します。これにより、文全体の意味を把握します。
【例】
モデルは「大規模言語モデル」の各トークンの関係性を学習し、文脈を理解します。
例えば、「大規模」が「言語モデル」と関連していることを学習します。
Step5:特徴量のエンコード(Feature Encoding)
文脈をもとに、モデルは特徴量をエンコード(情報やデータを特定の形式や表現に変換するプロセス)します。ここで言及する「特徴量」は主に文の意味的な表現や、トークンの位置情報を指します。
Step6:デコード(Decoding)
エンコードされた特徴量をもとに、モデルは次に続くトークンを生成します。デコード(エンコードされた情報や表現を元の意味や形式に変換するプロセス)では、文の一部または全体を生成します。
【例】
「大規模言語モデルは面白いですか?」に対して、「それは確かに面白いです!」というトークンを生成します。
Step7:確率分布の出力
モデルがデコードされた表現をもとに次のトークンを生成するとき、各可能なトークンに対してその出現の確率を計算します。これにより、モデルはどのトークンが最も適切かを定量的に評価します。
最終的な確率分布が得られたら、モデルはその中から最も確率の高い(もしくは適切と考えられる)トークンを選択します。これが次の生成ステップにおける出力となります。
【例】
「確かに」が80%、「面白い」が15%、「です」が5%の確率で出現すると計算されます。
Step8:トークンの生成とテキストへの変換
生成されたトークンをもとに、文章を逐次的に構築し、最終的に人間が理解できるテキストに変換します。
【例】
最終的に、モデルは確率分布から最も適切と考えられるトークンを選択し、「それは確かに面白いです!」というテキストを生成します。
LLM(大規模言語モデル)の活用分野
LLMは、自然言語処理のタスクにおいて広範囲に活用できます。具体的には検索エンジン、バーチャルアシスタント、チャットボットなどの分野で使用され、さらに以下のような多岐にわたる機能を提供します。
- 質問への回答
ユーザーの質問に対して自然な言葉で回答を生成、会話することができます。
- 文章の要約
長文を簡潔にまとめ、要約を生成する際に活用されます。
- コピーライティング
クリエイティブな文章生成や宣伝文の作成など、コピーライティングの補助に使用されます。
- コンテンツ生成
ブログ記事、ニュース記事、商品の説明文など、様々なコンテンツの生成が可能です。
- 研究補助
論文の概要や関連研究の整理、研究資料の作成などに利用されます。
- 言語翻訳
異なる言語間での文章翻訳において、高度な自然な翻訳を提供します。
LLMは大量のデータを学習し、自然言語の理解と生成に優れた能力を有しています。そのため、ビジネスプロジェクトなどで様々なタスクを自動化し、高度な自然言語処理技術を活かした応用も期待されています。
LLM(大規模言語モデル)の課題
LLMにもいくつかの課題があります。ここからは考えられる主な課題を5つご紹介します。
ステレオタイプとバイアス
大量のトレーニングデータから学習するLLM(大規模言語モデル)は、その特徴を引き継ぐため、元のデータに潜む人間特有の偏りや不公平性、ステレオタイプを反映し、バイアスの強い結果を生成する場合があります。
具体的には、学習データには多様な文化、ジェンダー、人種、社会的背景などが反映されていることから、ある特定のグループに対する偏見などが生成されるなどの可能性が考えられます。
幻覚(ハルシネーション)
LLM(大規模言語モデル)は、学習データに基づいて新しい情報を生成します。この過程で実際には存在しない情報や誤情報を、あたかも存在するかのように生成してしまう場合があり、これをAIの「幻覚」(ハルシネーション)といいます。
また、学習データには存在するが、実際には正確ではない情報もあります。学習データに偽りや不正確な情報が含まれてしまっている場合、その情報を元にモデルが新しい文章を構築する際に、事実とは異なる誤った情報が生み出される可能性があるということです。この結果、モデルが生成する回答に信頼性の低い情報が混入する可能性が生じます。
古い情報
LLMは訓練時のデータに基づいているため、訓練後に発生した新しい情報や出来事に対応できない可能性があります。
データプライバシー
LLMが大量のデータから学習するため、個人のデータプライバシーの問題が浮上します。
モデルの透明性
LLMの内部構造が非常に複雑であるため、モデルがどのような段階を踏んで結論に至ったかを理解することが難しい場合があります。
まとめ:LMM(大規模言語モデル)の概要を理解しよう
LLM(大規模言語モデル)は生成AIの一種で、自然言語処理に特化した大規模な言語モデルです。Transformerアーキテクチャをベースに、大量のテキストデータで学習することで、人間の言葉の意味や文脈を理解し、自然な文章を生成できるようになりました。
しかしデータのバイアスも内包しており、生成結果には信頼性の課題もあるという点も忘れてはいけません。
最後までご覧いただきありがとうございます。LLM(大規模言語モデル)についての理解は深まったでしょうか?
様々な活用方法の登場に期待しつつ、今後の展開にも注目していきましょう。
Web Auto Robotの「AUTORO」で業務自動化
AUTOROの製品紹介資料を無料でダウンロードいただけます。
製品の特徴や導入のメリット、ご活用事例などをご紹介しています。






